
告别简单的数据清洗:企业级 AI 需要“数据治理”
对于任何参与商业决策的 AI 系统而言,数据质量是其成败的关键。我们常强调“数据清理”的重要性,这确实是不可或缺的第一步。然而,在涉及重大决策的企业级 AI 应用中,仅靠数据清理还远远不够。为确保 AI 投资能够获得长期信任与稳定回报,企业必须建立起一套更为严格、持续运行的流程:数据治理。
为什么数据治理是企业 AI 战略的必需品?
在深入探讨数据治理的技术细节之前,我们必须首先理解:为何这种更深层次的数据准备工作对企业 AI 至关重要?近期研究为此提供了有力佐证。麻省理工学院2025年的一份报告明确指出:“AI 的成功,与其说取决于模型本身的复杂度,不如说更依赖于能否获取清洁、互联且高质量的数据流。” 1
这个道理可以通过一个生动的比喻来理解:数据清洗好比清洗蔬菜,重点是去除表面的泥土杂质;而数据治理,则如同专业厨师烹饪前的全套备料。它不仅要求每种食材干净无污染,更要求食材被精确地切割、称重、统一规格,并调整至最适合特定复杂菜谱的“理想状态”。对于驱动企业核心业务的 AI 模型来说,这样周全的准备绝非可有可无,而是确保其成功的必要前提。
隐形威胁:数据治理不足如何侵蚀 AI 效能
若 AI 模型长期输入未充分治理的数据,其性能可能在无人察觉中持续衰退。这种隐蔽而危险的趋势被称为数据漂移。麦肯锡(2025)报告警示:“缺少对数据漂移和输入质量的主动监控,仅不到5%的 AI 项目能长期保持性能稳定。” 2
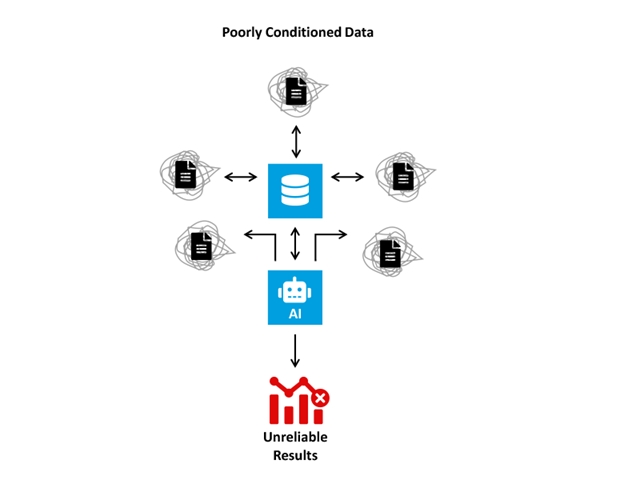
曾经高度精准的财务预测模型,若其所依据的经济数据特征悄然改变,便可能开始输出不可靠的结果;客户服务 AI 若未能及时捕捉用户行为的变化,则会逐渐提供令人困惑或无关的回应。若缺乏完善的数据治理流程来识别这些变化,企业无异于在迷雾中前行。
以客户流失预测模型为例:该模型基于稳定市场时期的数据训练而成。一旦经济环境突变,引发用户行为变化,例如消费金额减少或偏好转移,数据漂移便会发生。此时输入的数据已偏离模型最初学习的规律。如果缺乏能够检测此类漂移并触发模型重欣训练的调优流程,预测结果将越来越脱离实际,导致企业可能依据过时的判断,错误配置高达数百万的客户留存预算。
这会将企业置于巨大的运营与财务风险之中:AI 系统的输出不再可信,问题出现时难以追溯根源,更无法向审计或监管机构证明其决策的可靠性。
斯坦福 AI 指数(2025)报告明确指出:“在各行业 AI 系统运行故障中,超过半数可归因于数据质量衰退与治理缺失。” 3
AI 数据治理的核心环节
数据治理并非一次性操作,而是一个持续自动化的流程,涵盖多个关键环节。将这些环节系统化地融入 MLOps 生命周期,正是构建可靠企业级 AI 与脆弱实验性模型之间的本质区别。
Gartner(2024)已将数据血缘追踪、漂移监控与数据增强明确列为“可信 AI 基础设施的核心构成要素”,并预测这些能力将在未来两年内获得广泛采用。4
企业 AI 所需的标准:持续可信与长期可靠
建立规范化的数据治理体系,是为 AI 系统奠定坚实可信基础的关键。作为成熟的 MLOps(机器学习运维)生命周期的核心支柱,该流程不仅确保模型在部署初期表现智能,更保障其在长期运行中持续保持稳定可靠的输出。
全链路数据溯源在这一体系中尤为重要。它不仅是技术层面的“附加优势”,更是受监管行业企业运营中的必备要求。该机制使企业管理者能够充分信任 AI 系统输出的建议,从而果断做出数据驱动的决策——因为它能够清晰回应每个管理者对 AI 系统都应提出的两个根本问题:“结论的依据是什么?”以及“能否提供相应证明?”
正如麦肯锡(2025)报告所强调:“建立数据溯源与可追溯框架的企业,获得高层信任并将 AI 拓展至试点阶段之外的可能性,是未建立该框架企业的两倍。” 6
SEEBURGER BIS 平台如何保证优质数据随时用于 AI
SEEBURGER BIS (商务集成套件)提供强大的自动化工具,帮助您将数据治理无缝整合到日常运营与 MLOps 生命周期中。该平台如同一个工业级“智能工厂”,能够持续输出符合 AI 模型要求的高质量、可信数据。
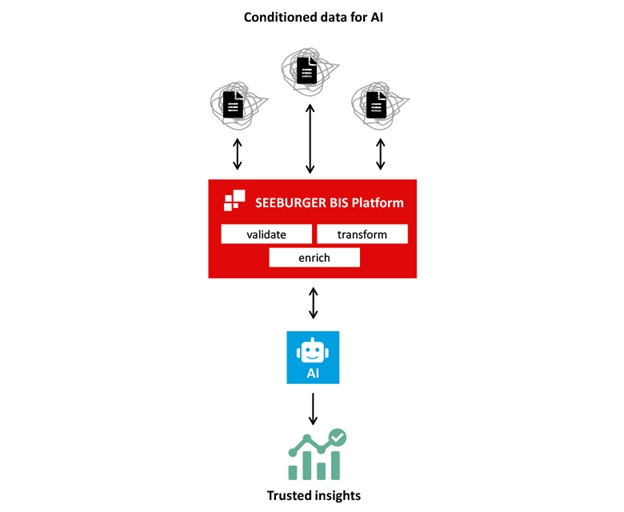
SEEBURGER BIS 平台远超基础的数据加载工具,它支持构建复杂的多阶段数据治理管道,实现端到端自动化:
- 全域连接与采集:无缝对接并获取企业内所有源系统的数据,支持本地与云端混合环境。
- 规则化转换与验证:借助强大的可视化工作流引擎,基于具体业务规则进行数据转换与校验。
- 智能化数据增强:灵活融合来自 ERP、CRM 等系统的关联信息,为原始数据赋予业务情境。
- 全流程 MLOps 协同:统一管理从数据接入、治理到输送至 AI 模型的完整生命周期。平台还可配置为在检测到数据漂移时,自动触发模型重新训练流程。值得一提的是,iPaaS(集成平台即服务)是实现此类 AI 协同运作的重要基础。
Gartner(2024)研究指出,具备先进数据治理能力的集成平台已被视为“实现企业级 AI 韧性及风险控制的核心推动力”。7
该平台带来的核心商业价值在于建立信任与降低风险。通过自动化数据治理流程,并提供可解释性所需的完整数据溯源,SEEBURGER BIS 平台持续保障驱动 AI 的数据兼具适用性与完整性。这不仅帮助企业规避因模型性能隐性退化带来的重大风险,也为在关键业务中规模化部署 AI 奠定了可靠的信任基础。
1 麻省理工学院 NANDA 计划(MIT NANDA Initiative),《2025年 AI 在商业中的应用现状报告》。马萨诸塞州剑桥市:麻省理工学院,2025年7月。
2 麦肯锡公司(McKinsey & Company),《 AI 发展现状:组织如何重构以获取价值》。2025年3月。
3 斯坦福大学 HAI 研究中心(Stanford HAI),Nestor Maslej 等,《2025年 AI 指数年度报告》。2025年4月。
4 高德纳公司(Gartner, Inc.),《技术影响雷达:生成式人工智能》。康涅狄格州斯坦福德:Gartner 研究,2024年5月。
5 麻省理工学院 NANDA 计划(MIT NANDA Initiative),《2025年 AI 在商业中的应用现状报告》。马萨诸塞州剑桥市:麻省理工学院,2025年7月。
6 麦肯锡公司(McKinsey & Company),《 AI 发展现状:组织如何重构以获取价值》。2025年3月。
7 高德纳公司(Gartner, Inc.),《技术影响雷达:生成式人工智能》。康涅狄格州斯坦福德:Gartner 研究,2024年5月。


